







In some situations, the scanf() function has one glaring weakness you need to fit the enter key before the function can be accepted what we have a type.
This is overcome by the getch( ) function, which will read a single character the instant it is typed without waiting for enter key to be typed followed character.
That you typed the getchar() is a macro and whereas the scanf( ) is a function.
The getchar( ) takes a single character at a time whereas scanf( ) can accept any number of inputs from the keyboard.
Scanf( ) accepts different type of data types whereas getchar( ) accepts only the character constants or digits or characters.

SOFTWARE MYTHS
Myths are widely held but false beliefs and views which propagate misinformation and confusion.
Three types of myth are associated with software:
- Management myth
- Customer myth
- Practitioner’s myth
MANAGEMENT MYTHS
• Myth(1)-The available standards and procedures for software are enough.
• Myth(2)-Each organization feels that they have state-of-art software development tools since they have the latest computer.
• Myth(3)-Adding more programmers when the work is behind schedule can catch up.
• Myth(4)-Outsourcing the software project to a third party, we can relax and let that party build it.
CUSTOMER MYTHS
• Myth(1)- General statement of objective is enough to begin writing programs, the details can be filled in later.
• Myth(2)-Software is easy to change because the software is flexible.
PRACTITIONER’S MYTH
• Myth(1)-Once the program is written, the job has been done.
• Myth(2)-Until the program is running, there is no way of assessing the quality.
• Myth(3)-The only deliverable work product is the working program
• Myth(4)-Software Engineering creates voluminous and unnecessary documentation and invariably slows down software development.


Data management is the development and execution of architectures, policies, practices, and procedures in order to manage the information lifecycle needs of an enterprise in an effective manner. The effective management of corporate data has grown in importance as businesses are subject to an increasing number of compliance regulations. Furthermore, the sheer volume of data that must be managed by organizations has increased so markedly that it is sometimes referred to as big data.
Big data management is the organization, administration, and governance of large volumes of both structured and unstructured data. The goal of big data management is to ensure a high level of data quality and accessibility for business intelligence and big data analytics applications. Corporations, government agencies, and other organizations employ big data management strategies to help them contend with fast-growing pools of data, typically involving many terabytes or even peta bytes of information saved in a variety of file formats. Effective big data management helps companies locate valuable information in large sets of unstructured data and semi-structured data from a variety of sources, including call detail records, system logs and social media sites.

Definition: A method of representing the step – by – step logical procedure for solving a problem in natural language (like English, etc.) is called an algorithm.
Algorithm can also be defined as an ordered sequence of well-defined and effective operations that, when executed, will always produce a result and eventually terminate in a finite amount of time. Note: Algorithm written in English language is called Pseudo code.
Properties an Algorithm should possess:
a. Generality: The algorithm must be complete in itself so that it can be also used to solve all problems of a specific type for any input data.
b. Input / Output: Each algorithm can take zero; one or more input data and must produce one or more output values.
c. Optimization: Unnecessary steps should be eliminated so as to make the algorithm terminate an infinite number of steps.
d. Effectiveness: Each step must be effective in the sense that it should be primitive (easily convertible into a program statement) and can be performed exactly in a finite amount of time.
e. Definiteness: Each step of the algorithm should be precisely and unambiguously stated.
The following are the various steps involved in program development.
1. Problem definition.
2. Problem Analysis and design.
3. Algorithm.
4. Flow chart.
5. Coding and implementation
6. Debugging and testing.
7. Documentation.
(1) Problem Definition: The problem definition phase is a clear understanding of exactly what is needed for creating a workable solution. We must know exactly what we want to do before we begin to do it. Defining the problem means understanding the problem. It involves the three specifications regarding a problem solution.
1. Input specification: Input specification makes what input is to be required for the problem solution and format.
2. Output specification: It gives the information that what output is going to be produced its type and format
3. Special processing: Special processing gives the probable for the smooth process of the next phases.
(2) Problem Analysis and Design: Before going to make a final solution to the problem must be analyzed. Outline solution is prepared for simple problems and in the case of complex problems; the main problem is divided into sub-problems called modules. These sub-problems can be handled and can be solved independently. When the task is too large, it always betters to analyses the task such that it can be divided into a number of modules and seeks a solution for each module.
(3) Algorithm: Once the problem is divided into modules, and the purpose of each module is clear, the logic for solving each module can be developed. The logic is expressed step by step. A step by step procedure to solve the given problem is known as an algorithm. An algorithm is defined as a finite set of instructions; which accomplish a particular task. An algorithm can be described in a natural language such as English, but each step is finite, feasible, and effective.
(4) Flow chart: After the completion of the algorithm, the program flow can be visualized by drawing the flow chart for the algorithm. A flow chart is nothing but a pictorial representation of how instructions will be executed one after the other.
(5) Coding & Implementation: Coding is a process of converting the algorithmic solution or flow chart into a computer program. In this process, each and every step of an algorithm will be converted into instructions of a selected computer programming language. Before selecting a programming language we must follow the following three considerations.
(a) Nature of the problem
(b) Programming language available on the computer system.
(c) Limitations of the computer. Coding will become easy, if the algorithmic solution is expressed properly. Once the coding is completed, the program is fed into the computer using a compiler to produce equivalent machine language code.
(6) Debugging & Testing: Before loading the program into the computer, we must locate and correct all the errors. The process of correcting errors in a program is called debugging. There are 3 types of errors that generally occur in a program namely,
a) Syntax Errors: Violation of the grammatical rules of the computer programming language is called a syntax error. This will occur during the compilation of the program.
b) Runtime Errors: The runtime errors will occur when the program is in execution. These errors are difficult to identify and these sometimes stop the execution of the program.
c) Logical Errors: Logical errors are very difficult to detect and correct. If a logical error occurs in a program, the program will run, but produces incorrect results.
It is very important to test the program written to achieve a specific task. Testing involves running the program with known data of which the results are known. As results are known, the results produced by the computer can be verified.
7) Documentation: Documentation is the most important aspect of programming. It is a continuous process to keep the copy of all the phases involved in problem definition, and details of the problem such as algorithm, flow chart, coding, and testing are the parts of the documentation. This phase involves producing written documents for the user.

Computer programmers use artificial languages, known as programming languages, to write the instructions that tell computers what to do. Programming languages have evolved over time to become more like the natural languages that human beings speak. The evolution from machine language to fifth-generation language is as below.
Levels of Programming Language:
First Generation Programming Language: The first generation of programming language, or 1GL, is machine language. Machine language is a set of instructions and data that a computer's central processing unit can execute directly. Machine language statements are written in binary code, and each statement corresponds to one machine action.
Second Generation Programming Language: The second-generation programming language, or 2GL, is assembly language. Assembly language is the human-readable notation for the machine language used to control specific computer operations. An assembly language programmer writes instructions using symbolic instruction codes that are meaningful abbreviations or mnemonics. An assembler is a program that translates assembly language into machine language.
Third Generation Programming Language: The third generation of programming language, 3GL, or procedural language uses a series of English-like words, which are closer to human language, to write instructions. High-level programming languages make complex programming simpler and easier to read, write, and maintain. Programs written in a high-level programming language must be translated into machine language by a compiler or interpreter. PASCAL, FORTRAN, BASIC, COBOL, C, and C are examples of third-generation programming languages.
Fourth Generation Programming Language: The fourth-generation programming language or non-procedural language, often abbreviated as 4GL, enables users to access data in a database. A very high-level programming language is often referred to as a goal-oriented programming language because it is usually limited to a very specific application and it might use syntax that is never used in other programming languages. SQL, NOMAD, and FOCUS are examples of fourth-generation programming languages.
Fifth Generation Programming Language: The fifth-generation programming language or visual programming language, is also known as natural language. Provides a visual or graphical interface, called a visual programming environment, for creating source codes. Fifth-generation programming allows people to interact with computers without needing any specialized knowledge. People can talk to computers and voice recognition systems can convert spoken sounds into written words. Prolog and Mercury are the best known fifth-generation languages.
C supports the idea of programmers creating their own data types.
Ordinal Data Types :
Ordinal data types have the following characteristics:
1. There exists a smallest value in the set of values.
2. There exists the largest value in the set of values.
3. There exists an order of values from the smallest to the largest.
Example:
The “char” data type is an ordinal data type. Each character value has an integer value associated with it. There are 256 characters.
1. The smallest character value has the ASCII value of 0.
2. The largest character value has the ASCII value of 255.
3. The sequence of ASCII values is 0, 1, 2,......., 253, 254, 255.
‘A’ == 65 ‘B’ == 66 ‘C’ == 67 etc....
The data types that are defined by the user are called user-defined derived data types.
1. Enumeration(enum)
2. Typedef defined DataType(typedef)
1. Enumeration: Enumeration (or enum) is a user-defined data type in C. It is mainly used to assign names to integral constants, the names make a program easy to read and maintain.
Syntax: enum State {Working = 1, Failed = 0};
Eg:
#include
enum week { Mon, Tue, Wed,Thur, Fri, Sat, Sun };
int main()
{
enum week day;
day = Wed;
printf(“%d”,day);
return 0;
}
2. Typedef defined DataType (typedef):
Using typedef does not actually create a new data class, rather it defines a name for an existing type.
This can increase the portability(the ability of a program to be used across different types of machines. i.e., mini, mainframe, micro, etc without much changes into the code)of a program as only the typedef statements would have to be changed.
Syntax: typedef type name;
-Arrays are defined in much the same manner as ordinary variables, except that each array name must be accompanied by a size specification (i.e., the number of elements).
-An array is a collection of variables of the same type that are referred to through a common name. A specific element in an array is accessed by an index.
-An array is a group of related data items that share a common name.
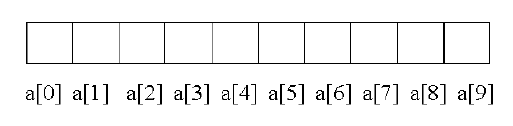
-The individual values are called elements. The elements are: a[0], a[1], a[2] .......a[9].
-The name of the array(a) contains the address of the first location i.e., a[0].
-The elements are stored in continuous memory locations during compilation.
-The elements of the array are physically and logically adjacent. When an array is passed as an argument to a function, its address is actually passed.
-The lowest address corresponds to the first element and the highest address to the last element.
-For a one-dimensional array, the size is specified by a positive integer expression(size), enclosed in square brackets. The expression is usually written as a positive integer constant.
-In general terms, a one-dimensional array definition may be expressed as
storage_class data_type array[ expression] ;
-The storage-class is optional, default values are automatic(auto) for arrays that are defined within a function or a block, and external( extern)for arrays that are defined outside of a function.
Eg: Several typical one-dimensional array definitions are shown below.
int x[100];
char text[80];
static char message[25];
static float n[12];
Integer arrays
int a[10];
/*defines an array a of size 10, as a block of 10 contiguous elements in memory */
Character Arrays
char name[11];
-To define a character array, need to define an array of size n+1 characters. This is because all character arrays are terminated by a NULL character (“\0”).
-Where name[0] through name[9] will contain the characters comprising the name, and name[10] will store the NULL character.

Types of Arrays
Basically, arrays can divide into two types. They are:
1. One Dimensional Array:
- An array with only one subscript is called a one-dimensional array or 1- d array. It is used to store a list of values, all of which share a common name and are separable by subscript values.
2. Two Dimensional Array:
- An array with two subscripts is termed a two-dimensional array.
- A two-dimensional array, it has a list of given variable-name using two subscripts. We know that a one-dimensional array can store a row of elements, so, a two-dimensional array enables us to store multiple rows of elements.
One-dimensional Arrays:
-The general form of declaring a one-dimensional array is
data_type array_name [size];
-Where data-type refers to any data type supported by C, array-name should be a valid C identifier, the size indicates the maximum number of storage locations (elements) that can be stored.
The general form of initializing an array of one-dimension is as follows:
data_type array_name [size] = {list of values};
-The values in the list are separated by commas.
-One array is used to store a group of values. A loop (using, for loop) is used to access each value in the group.
Two-dimensional array:
-An array with two subscripts is termed a two-dimensional array.
Eg: int a[] [];
-A two-dimensional array, it has a list of given variable -name using two subscripts. We know that a one-dimensional array can store a row of elements, so, a two-dimensional array enables us to store multiple rows of elements.
Eg: A table of elements or a Matrix representation.
-The syntax of declaring a two-dimensional array is:
data_type array_name [rowsize] [ colsize];
-Row size and column size should be integer constants.
-Total number of location allocated = (row size * column size).
-Row-number range from 0 to rowsize-1 and column-number range from 0 to colsize-1.
Eg: int m[3] [3];
Applications of Arrays:
1. Arrays are used to store a list of values.
2. Arrays are used to Perform Matrix Operations ( Addition, Multiplication & Transpose)
3. Arrays are used to implement Search Algorithms. ( Linear Search & Binary Search).
4. Arrays are used to implement Sorting Algorithms ( Insertion Sort, Bubble Sort, Selection Sort, Quick Sort, Merge Sort, etc.,).
5. Arrays are used to implement Data structures ( Stacks & Queues).
6. Arrays are also used to implement CPU Scheduling Algorithms.

A Preprocessor is system software (a computer program that is designed to run on a computer's hardware and application programs). It performs preprocessing of the High-Level Language(HLL).
The preprocessor doesn't know about the scope rules of C. Preprocessor directives like #define come into effect as soon as they are seen and remain in effect until the end of the file that contains them the program's block structure is irrelevant.
We can place these preprocessor directives anywhere in our program. Examples of some preprocessor directives are: #include, #define, #ifndef etc.
There are 4 main types of preprocessor directives:
1. File Inclusion
2. Macros
3. Conditional Compilation
4. Other directives
1. File Inclusion:
i. Header File or Standard files: These files contains the definition of pre-defined functions like printf(), scanf(), etc. These files must be included for working with these functions. Different functions are declared in different header files.
Eg: #include < stdio.h>
ii. User-defined files: When a program becomes very large, it is good practice to divide it into smaller files and include them whenever needed. These types of files are user-defined files.
Eg: #include “filename”
2. Macros: Macros are a piece of code in a program that is given some name. Whenever this name is encountered by the compiler the compiler replaces the name with the actual piece of code. The ‘#define’ directive is used to define a macro.
Eg: #define LIMIT 5
Note: There is no semi-colon(‘;’) at the end of the macro definition. Macro definitions do not need a semi-colon to end.
3. Conditional Compilation: Conditional Compilation directives are a type of directives that help to compile a specific portion of the program or to skip compilation of some specific part of the program based on some conditions. This can be done with the help of two preprocessing commands ‘ ifdef ’ and ‘ endif ’.
Eg:
# ifdef macro_name
statement 1;
statement 2;
statement 3;
. . .
statement N;
#endif
If the macro with the name as ‘macro_name’ is defined then the block of statements will execute normally but if it is not defined, the compiler will simply skip this block of statements.
4. Other directives:
#undef is used to destroy a macro that was already created using #define.
#ifdef returns TRUE if the macro is defined and returns FALSE if the macro is not defined.
#ifndef returns TRUE if the specified macro is not defined otherwise returns FALSE.
#if uses the value of specified macro for conditional compilation.
#else is an alternative for #if.
#elif is a #else followed by #if in one statement.
#endif is used to terminate preprocessor conditional macro.
#error is used to print an error message on stderr.
#pragma Directive: This directive is a special purpose directive and is used to turn on or off some features. This type of directives are compiler-specific i.e., they vary from compiler to compiler.
#pragma startup and #pragma exit: These directives help us to specify the functions that are needed to run before program startup( before the control passes to main()) and just before program exit (just before the control returns from main()).

C supports a number of string handling functions. All of these built-in functions are aimed at performing various operations on strings are in the header file string.in
(i) strlen( )
This function is used to find the length of the string excluding the NULL character. In other words, this function is used to cout the number of character in a string. Its syntax is as follows:
Int strlen(string);
Example: char str1[ ]="WELLCOME";
int n;
n =strlen(str1);
/* A program to caculate length of string by using stren() function */
#include
main()
{
char string1[50];
int length;
printf("\n Enter any string:");
gets(string1);
length=strlen(string1);
printf("\n The length of string=%d",length);
}
(ii) strcpy( )
This function is used to copy one string to the other. Its syntax is as follows:
strcpy(strings1,strings2);
Where string1 and string2 are one -dimmensional character arrays.
This function copies the content of strings2 to string1.
E.g.,string1 contains master and string2 contains madam, then string1 holds madam after the execution of strcpy(string1,string2) function.
Example : char str1[ ] ="WELLCOME";
char str2[ ]="HELLO";
strcpy(str1,str2);
/* A program to copy one string to another using strcpy( ) function */
#include
#include
main( )
{
char string1[30],string2[30];
printf("\n Enter first string:");
gets(string1);
printf("\n Enter second string:");
gets(string2)
strcpy(string1,string2);
printf("\n first string=%s",string1);
printf("\n second string=%s",string2);
}
(iii) strcmp( )
This function compares two stings characters by character b(ASCII comparison) and returns one of three values {-1,0,1}. The numeric difference is'0' if strings is equal. If it is negative string1 is alphabetically above string2. If it is positive string2 is alphabetically above string1.
Its syntax is as follows:
int strcmp(string1,string2);
Example: char str1[ ]="ROM";
char str2[ ]="RAM";
strcmp(str1,str2);
(or)
strcmo("ROM","RAM");
/* a program to compare two strings using strcmp() function */
#incudestdio.h>
#include
main()
{
char string1[30],string2[15];
int x;
prinf(""\n Enter first string:");
gets(string1);
printf("\n Enter seond string:");
gets(strings2);
x= strcmp(string1,string2);
if(x==0)
printf("\nBoth strings are equal");
else if(x>0)
printf("\n first string is bigger");
else
printf("\n second string is bigger");
}
(iv) strcat ( )
This fuction is used to concatenate two strings. i.e.,it appends one string at the end of the specified string.Its syntax as follows:
strcat(string1,string2);
where string1 and string2 are one-dimensional character arrays.
This function joins two strings together. In other words, it adds the string2 to string1 and the strings1 contains the concatenated string. E.g.,string1 contains prog and string2 contains ram , then string1 holds program after the execution of the strcat( ) function.
Example: char str1[10] = "VERY";
char str2[5] = "GOOD";
strcat(str1,str2);
/* A program to concatenate one string with another using stracat( ) function */
#include
#include
main( )
char string1[30],string2[15];
printf("\n Enter first string:");
gets(string1);
printf("\n Enter second string:");
gets(strings2);
strcat(string1,string2);
printf("\n concatenated string=%s",string1);
}
Useful Files
Users Joined


